
Pratik Khedekar | Data Scientist
When writing code is no longer the differentiator, everything else becomes the job
Not long ago, being a strong coder was the foundation of every data and AI role. Your value was largely tied to how efficiently you could wrangle a dataset, build a model pipeline, or ship a feature. That era is not over, but it is changing faster than most job descriptions reflect.
AI coding assistants can now generate, debug, and refactor code in seconds. AI agents can run end-to-end workflows, orchestrate data pipelines, and automate model evaluation loops. The mechanics of writing code are becoming commoditised. And when that happens, the question every data and AI professional needs to sit with is: if the code writes itself, what exactly do I bring to the table?
The shift nobody talks about openly
Most conversations about AI replacing jobs focus on the extremes: either panic about mass displacement or dismissive assurances that nothing will really change. The more useful conversation is the one in the middle.What is happening across data and AI roles is not replacement. It is a layer shift. The mechanical, syntactical, execution-level work is moving down to AI tools. The interpretive, contextual, judgment-heavy work is moving up in importance. Roles that were once 70 percent execution and 30 percent thinking are flipping closer to the reverse. That sounds like an upgrade. In many ways it is. But it also means the skills that made someone excellent five years ago are no longer sufficient on their own. Here is what each role looks like through that lens.
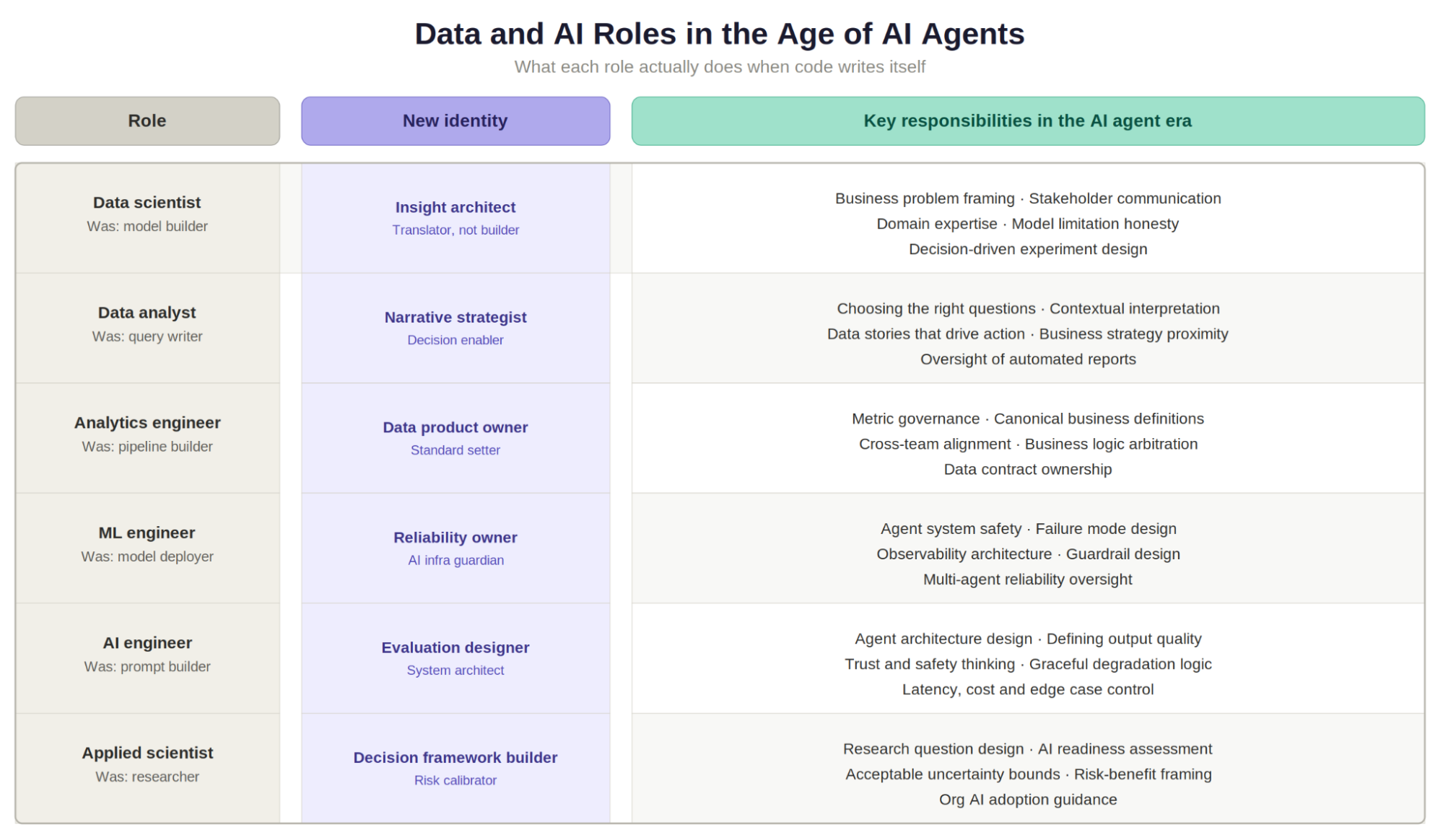
Data scientist: From model builder to insight architect
The traditional data scientist spent a significant portion of their week on data wrangling, feature engineering, and iterating on model code. That work has not disappeared, but AI agents now compress its timeline dramatically. A data scientist who once spent two days building a baseline model can now get there in a few hours with AI-assisted tooling.
What fills the time that opens up? The work that was always the most valuable but rarely had enough space: deeply understanding the business problem before touching data, questioning whether a model is even the right solution, communicating findings to people who do not speak statistics, and designing experiments that generate decisions rather than just results.
The new data scientist is less a builder and more a translator. They sit at the boundary between what the data can tell you and what the organisation actually needs to hear. Domain expertise, stakeholder communication, and intellectual honesty about model limitations become their sharpest tool
Data analyst: From query writer to narrative strategist
The analyst role has already been evolving for years, and AI accelerates it further. Natural language querying, automated dashboards, and AI-generated reports mean that the raw act of pulling numbers is increasingly accessible to non-analysts.
This does not make analysts redundant. It makes the analysts who only pulled numbers redundant. The ones who survive and thrive are those who have always understood that the chart is never the point. The point is the decision the chart is supposed to inform.
In the agent era, the data analyst becomes a narrative strategist. Their job is to know which questions are worth asking, to apply context that no automated tool possesses, and to shape data stories that move people to act. They work closer to business strategy, closer to the decision-maker, and further from the SQL editor.
Analytics engineer: From pipeline plumber to data product owner
Analytics engineers built their reputation on bringing software engineering discipline to analytics workflows. They own the transformation layer, build semantic models, and make sure that the right data reaches the right people in a reliable, documented form.
AI tools are beginning to generate and maintain dbt models, write documentation automatically, and suggest schema optimisations. The craft of assembling a transformation pipeline is becoming easier to automate.What remains irreplaceable is the judgment layer. Which metrics should be canonical? How should business logic be encoded into the data model? When two departments define the same concept differently, who arbitrates? The analytics engineer of the future is less a pipeline plumber and more a data product owner. They set standards, govern definitions, and ensure that the data layer reflects how the organisation actually thinks about its business.
ML engineer: From model deployer to systems reliability owner
ML engineers have always bridged the gap between data science experimentation and production systems. They handle infrastructure, deployment, monitoring, and the unglamorous but critical work of keeping models working in the real world. AI agents are beginning to assist with parts of this: auto-scaling configurations, anomaly detection in model performance, and even automated retraining triggers. But the judgment calls around reliability, cost, safety, and failure modes are human territory.
The ML engineer in the agent era becomes more of a systems reliability owner for AI infrastructure. They design for observability, set guardrails around automated systems, and take responsibility for what happens when AI agents interact with each other in production. That last part is genuinely new and genuinely hard. Nobody has fully mapped the failure modes of multi-agent systems at scale yet, and the ML engineers who build intuition here early will be invaluable.
AI engineer: the role being defined in real time
The AI engineer title is relatively new and still loosely defined. In most organisations it refers to practitioners who build applications and systems on top of foundation models: designing prompts, building retrieval pipelines, integrating APIs, and orchestrating AI agents into coherent products.
Because the role is young, it is also where the shift from code to judgment is most visible. Building a basic LLM-powered application has become fast. Building one that works reliably, safely, and usefully is still genuinely difficult. The AI engineer’s core competency is becoming evaluation and system design. They think about trust, latency, cost, and edge cases. They design agent architectures that degrade gracefully when things go wrong. They define what good looks like for AI outputs in a specific context, which requires domain understanding and user empathy at least as much as technical skill.
Applied scientist: from researcher to decision framework builder
Applied scientists sit closer to research than product, but their work is expected to produce real-world impact. They bring rigour to empirical questions, design experiments, and often help organisations decide whether a particular AI capability is mature enough to deploy.
AI tools can accelerate literature reviews, generate hypotheses, and automate certain experimental setups. What they cannot do is define the right research question, calibrate risk tolerance, or decide when a result is good enough for a specific use case. The applied scientist becomes a decision framework builder. Their job is to give organisations the intellectual scaffolding to make confident choices about AI adoption, model quality, and acceptable uncertainty. That is a deeply human skill set that requires both scientific credibility and the ability to communicate under ambiguity.
The skills that cut across every role
Regardless of title, several capabilities are rising in importance across the board:
Systems thinking. The ability to reason about how AI components interact, fail, and produce unexpected emergent behaviours is becoming fundamental. Point solutions are giving way to interconnected agent pipelines, and understanding the whole system matters more than mastering any single part.
Evaluation design. As AI generates more outputs, the ability to define what good looks like and build robust evaluation frameworks is a critical skill. This is not just a technical problem. It requires clear thinking about values, tradeoffs, and what the output is actually for.
Communication and influence. When execution is automated, the ability to explain, persuade, and guide decisions becomes the primary value-add. Every data and AI role now benefits from stronger writing, clearer thinking, and genuine stakeholder empathy.
Ethical and risk reasoning. AI systems can fail in ways that cause real harm. Practitioners who can proactively identify risks, question assumptions, and advocate for responsible deployment are increasingly valued. This is not a soft skill anymore; it is a core competency.
Key takeaways
Code is no longer the moat. Every role is shifting from execution to judgment. The faster you internalise this, the more intentional you can be about where you invest your growth.
Your domain knowledge is now a differentiator. AI tools do not understand your industry, your users, or your organization’s constraints. You do. That contextual depth is irreplaceable.
Communication is not soft anymore. When AI handles more of the execution, a practitioner’s ability to ask the right questions, frame tradeoffs clearly, and influence decisions becomes their primary professional value.
Titles are lagging indicators. Your job description may not have changed yet, but the most valued version of your role already has. Do not wait for the org chart to tell you what to learn next.
The age of AI agents is not the end of the data and AI profession. It is the beginning of a more interesting version of it. The roles that survive and grow are not the ones that resist automation. They are the ones that move up the stack fast enough to stay ahead of it.
The best practitioners in every category listed above are already making this shift. They are spending less time writing boilerplate and more time thinking about why, for whom, and what happens when things go wrong.
That has always been the most important work. Now it is the only work that matters.